IA generativa e RAG
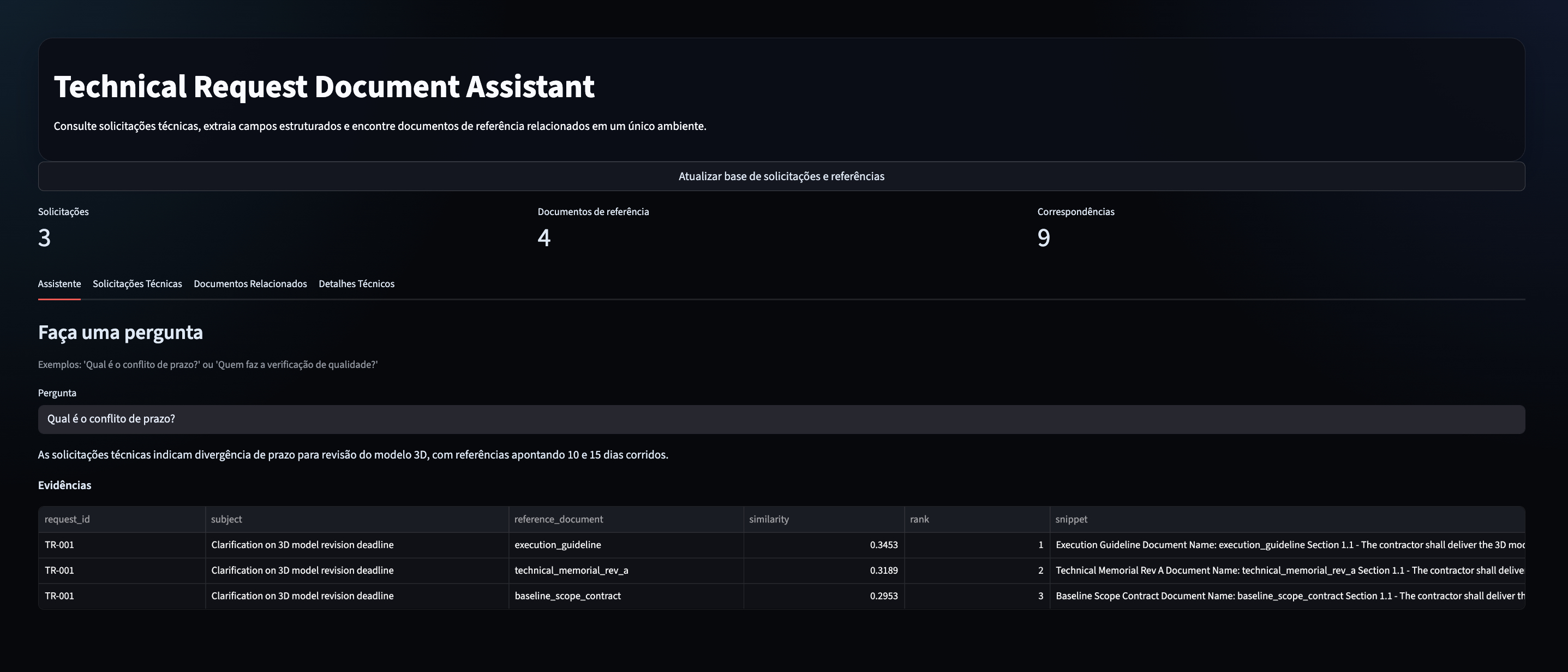
Assistente de IA generativa (RAG) para atendimento no setor público
Projetei e implementei um assistente de IA generativa (RAG) em produção para apoiar o atendimento sobre mais de 20 programas de bolsas, auxílios e prestação de contas no setor público federal, em dois canais: um app de consulta assistida e um assistente de redação de respostas no Outlook.
O que desenvolvi: arquitetura RAG completa com camada de respostas curadas (anti-alucinação), fila de curadoria, roteamento automático, observabilidade por programa e busca híbrida com fallback entre modelos.
Dados e analytics
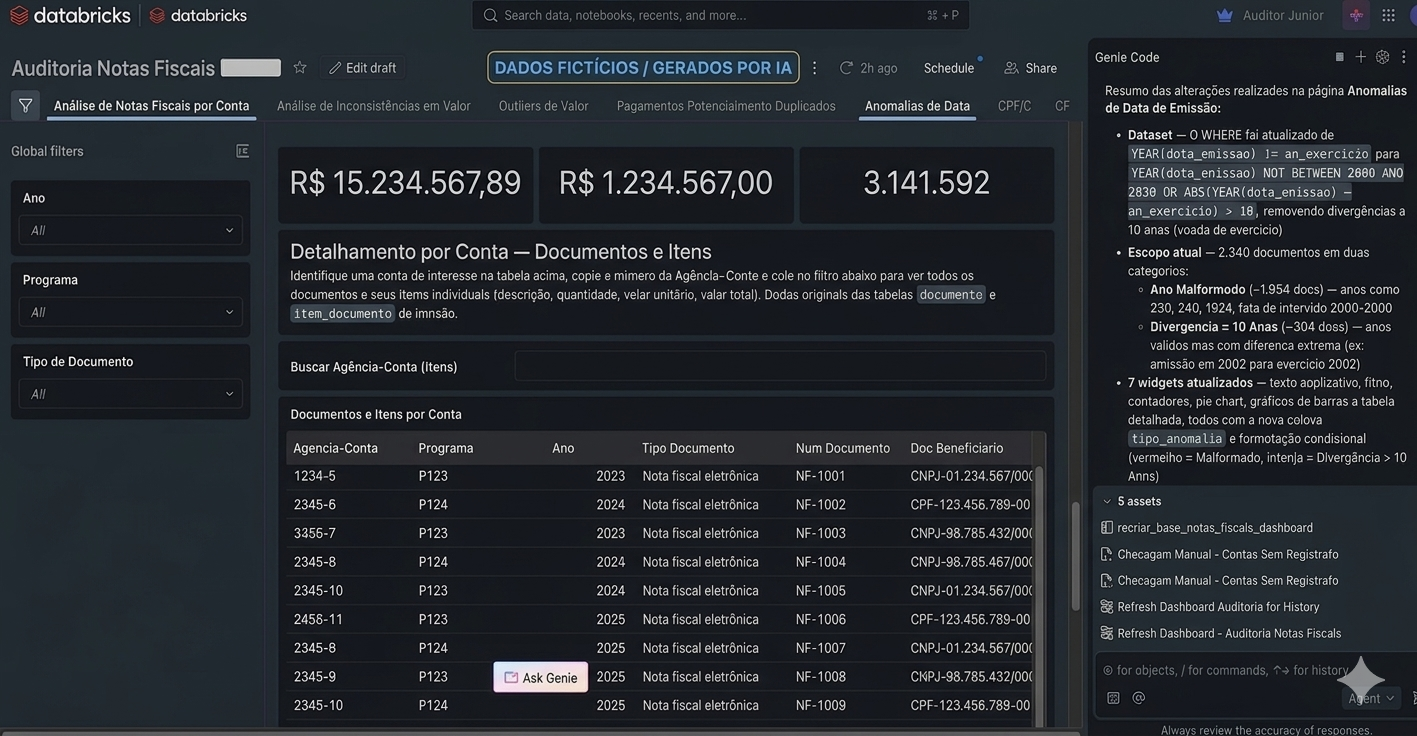
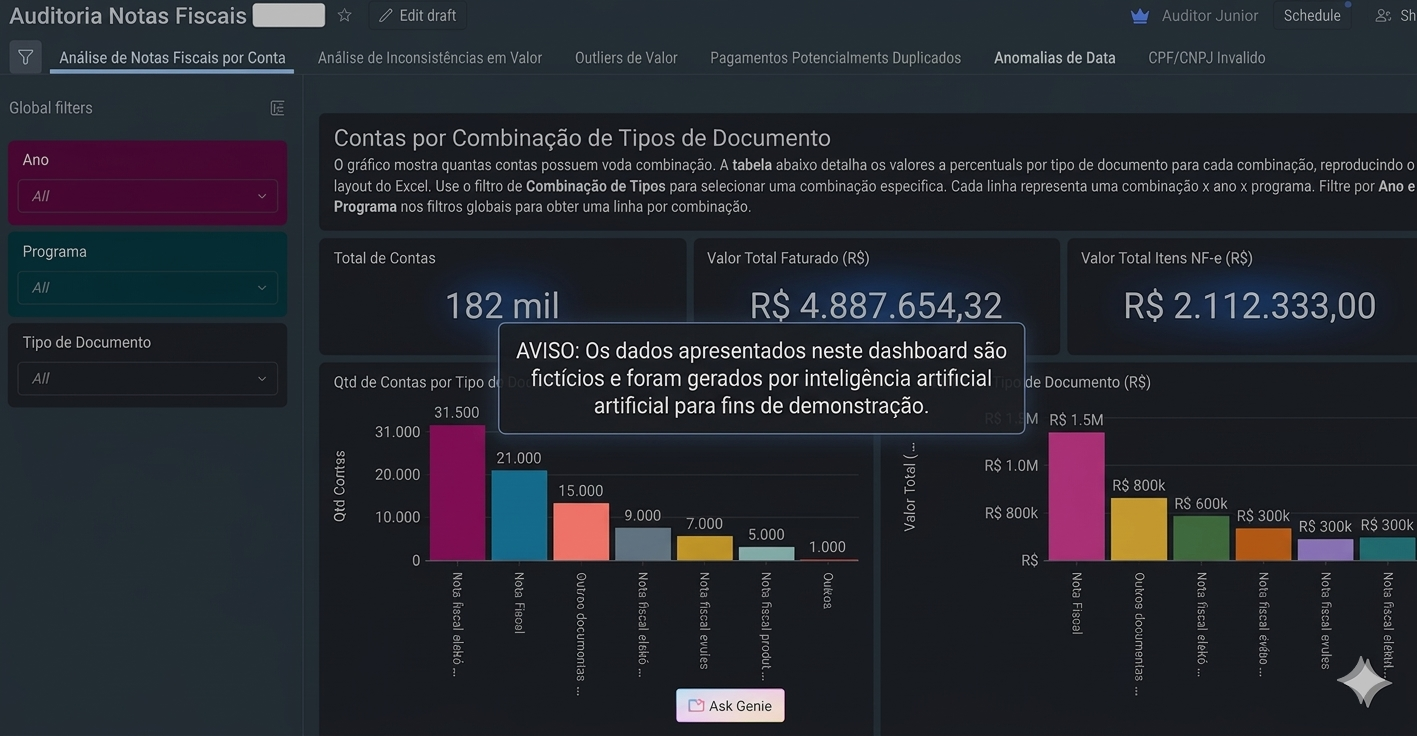
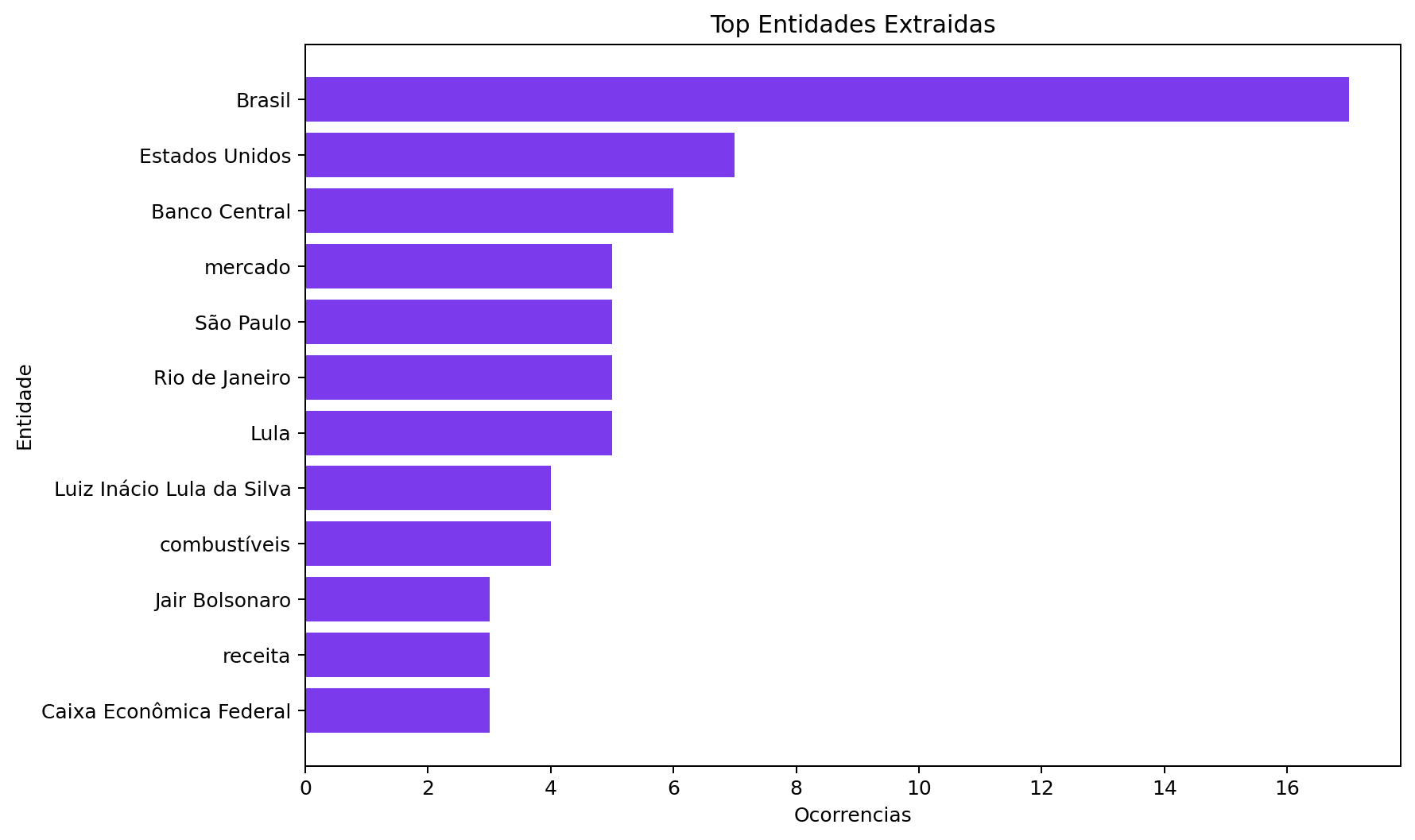
Auditoria de notas fiscais com PySpark, Databricks e Genie
Engenharia analítica em big data para investigar inconsistências
em transações, com tabelas analíticas, consultas em PySpark e dashboard.
Impacto: cerca de 20% de inconsistências
detectadas e redução de metade do tempo de auditoria.
Documentos e NLP
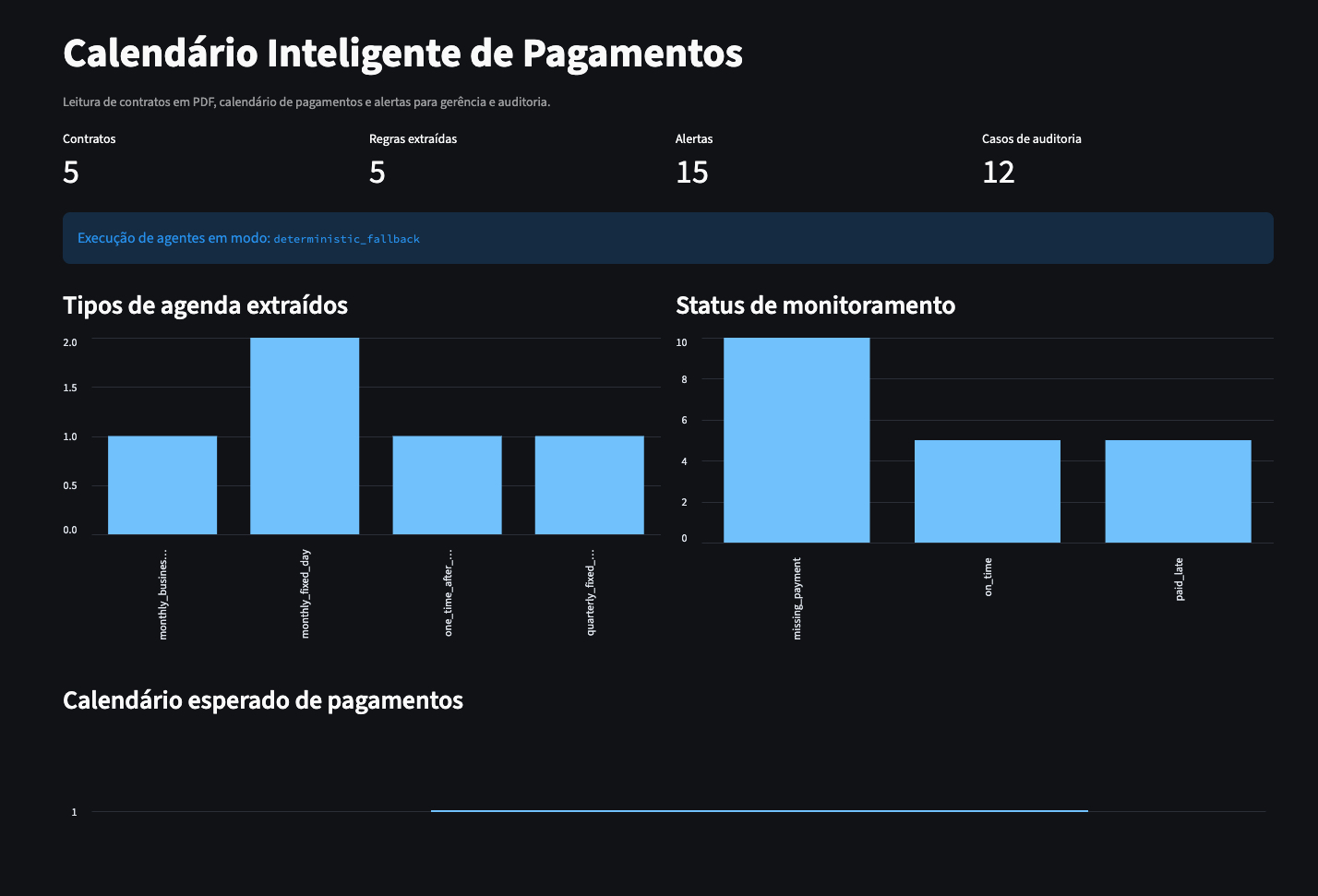
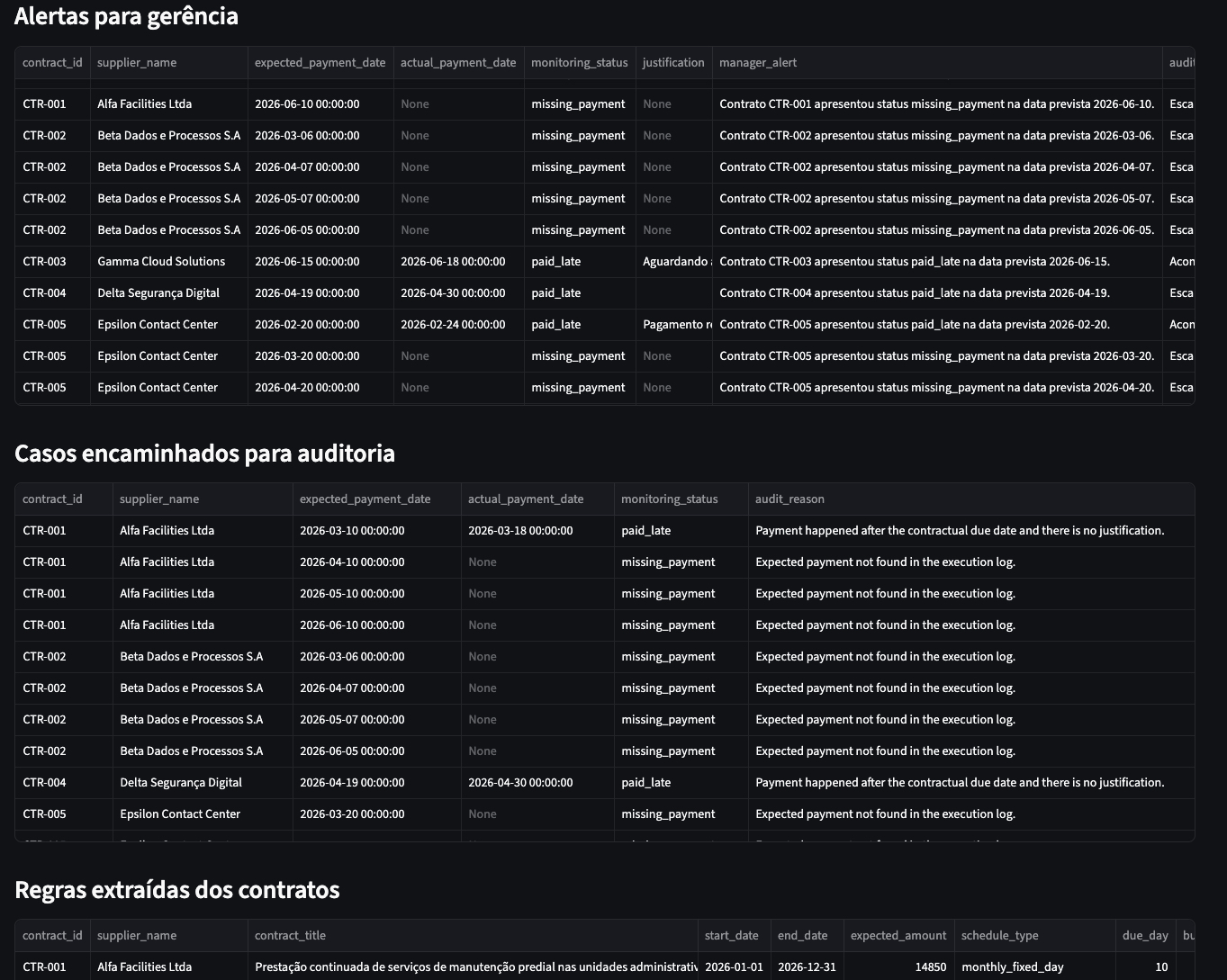
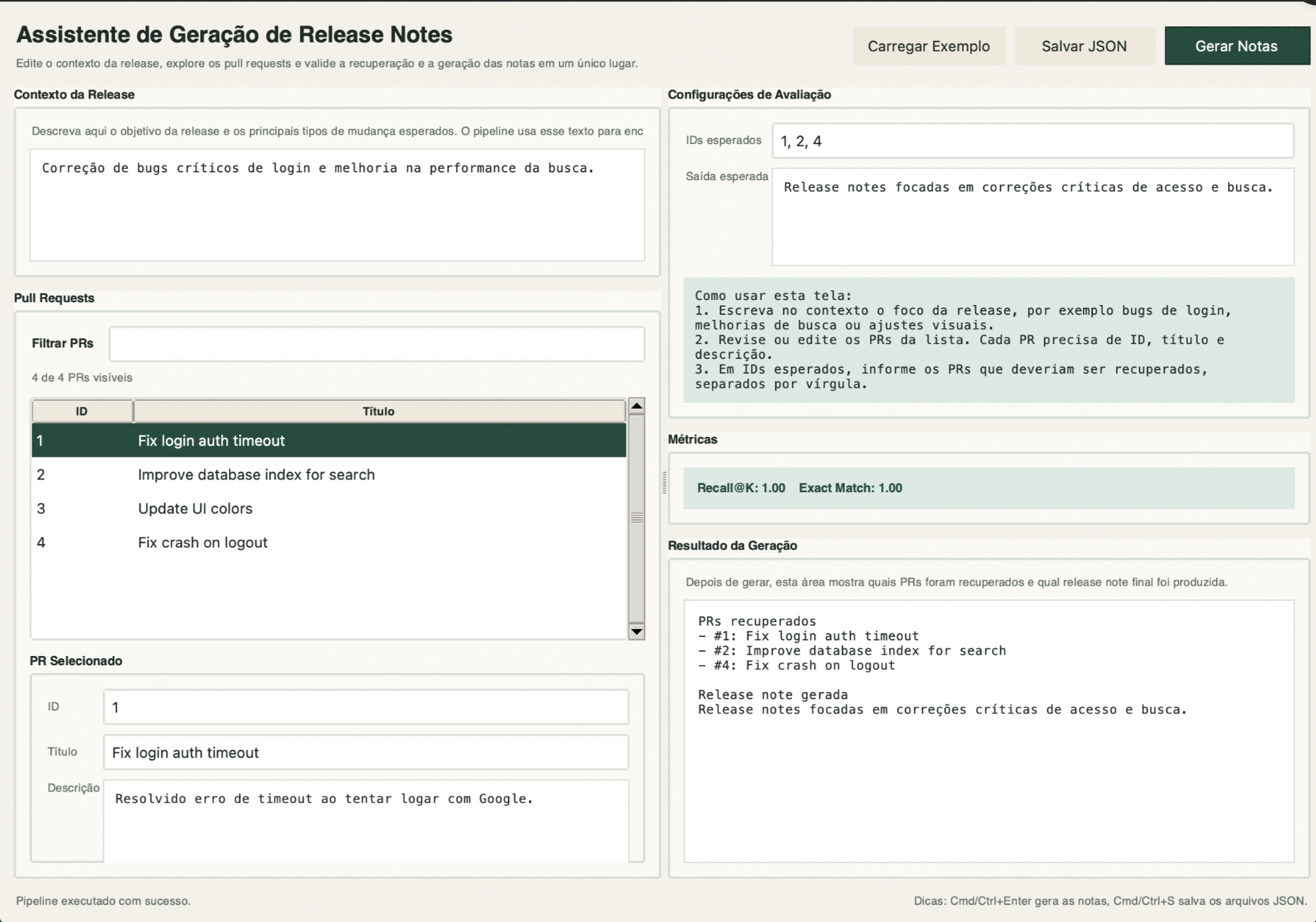
Leitura de contratos e calendário de pagamentos com IA
Extração de cláusulas financeiras de contratos em PDF, construção de
calendário esperado de pagamentos e monitoramento de divergências.
Impacto: contratos pagos na data correta,
gerando economia financeira direta e mais controle para a
auditoria interna.
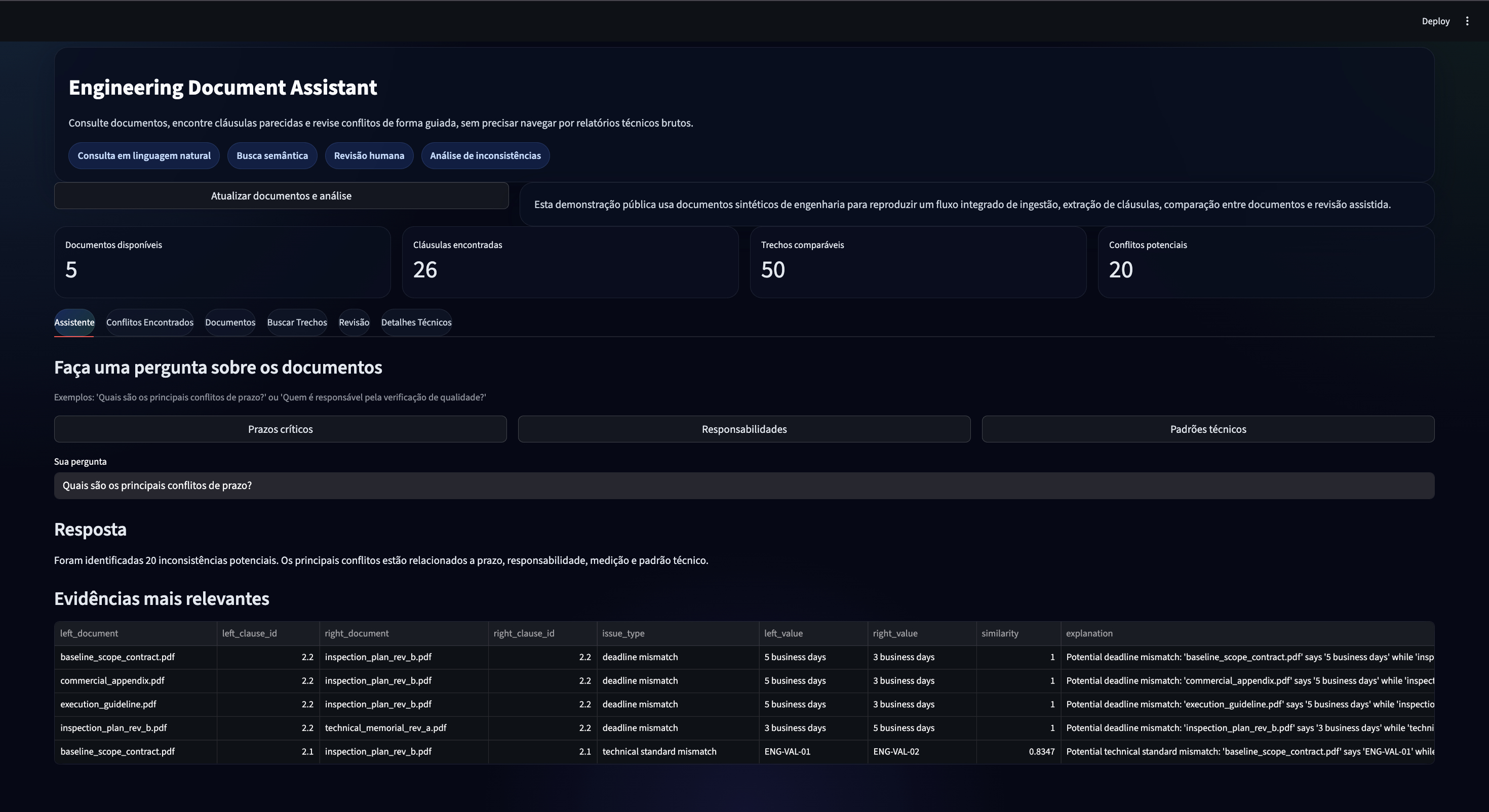
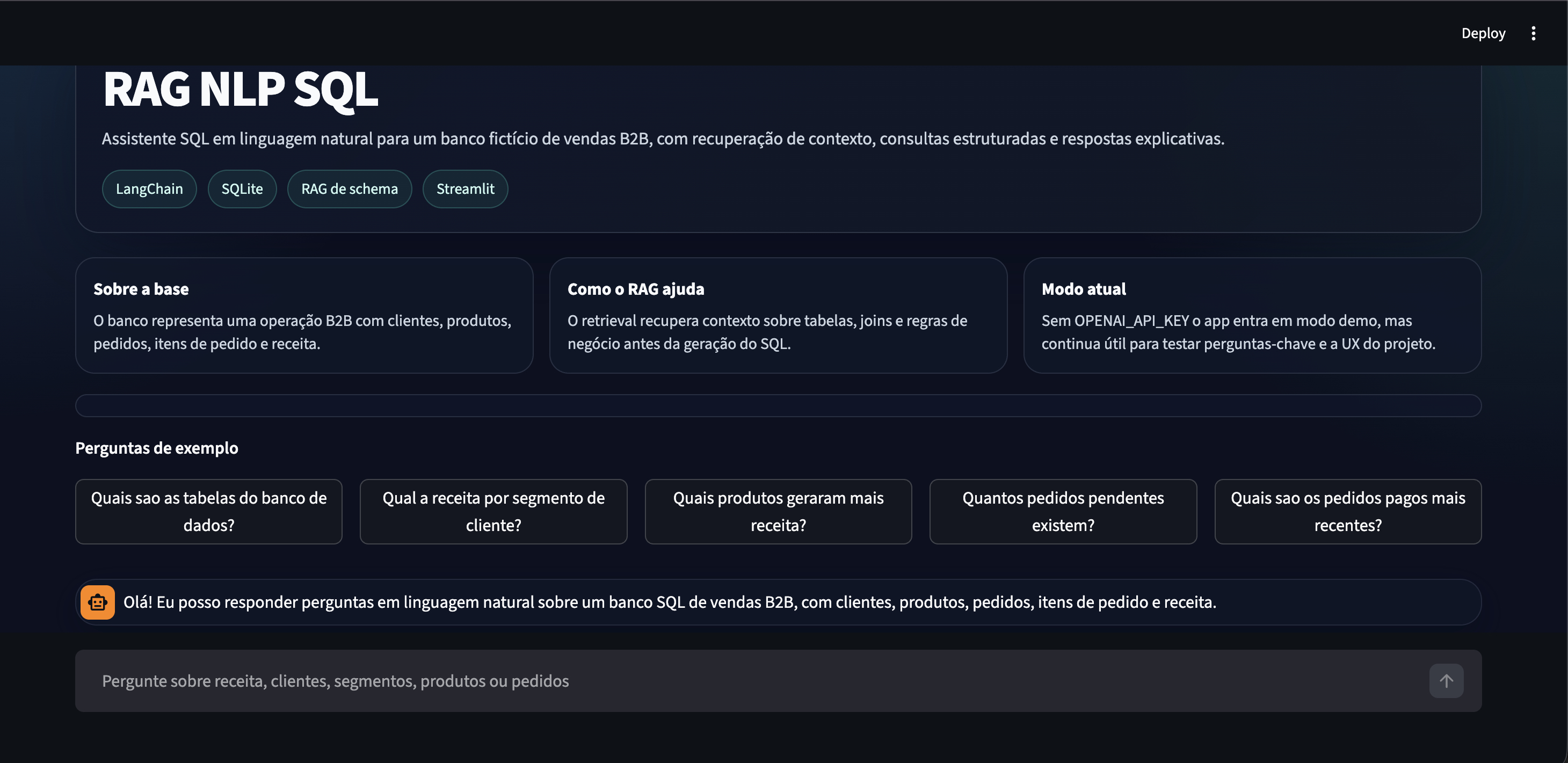
Busca e RAG
RAG NLP SQL com LangChain, OpenAI e SQLite
Perguntas em linguagem natural sobre base relacional, combinando
recuperação semântica do schema com geração e execução de SQL.
Agentes e plataforma
MCP Docs Assistant com FastMCP e busca BM25
Servidor MCP read-only para consulta de documentação local, expondo
recursos, ferramentas e prompts para clientes compatíveis com MCP.