Generative AI and RAG
Generative-AI (RAG) assistant for public-sector support
I designed and shipped a production generative-AI (RAG) assistant supporting 20+ scholarship, benefit and accountability programs in the federal public sector, across two channels: an assisted-consultation app and an Outlook reply-drafting assistant.
What I built: a full RAG architecture with a curated-answer layer (anti-hallucination), a curation queue, automatic routing, per-program observability and hybrid search with model fallback.
Data and analytics
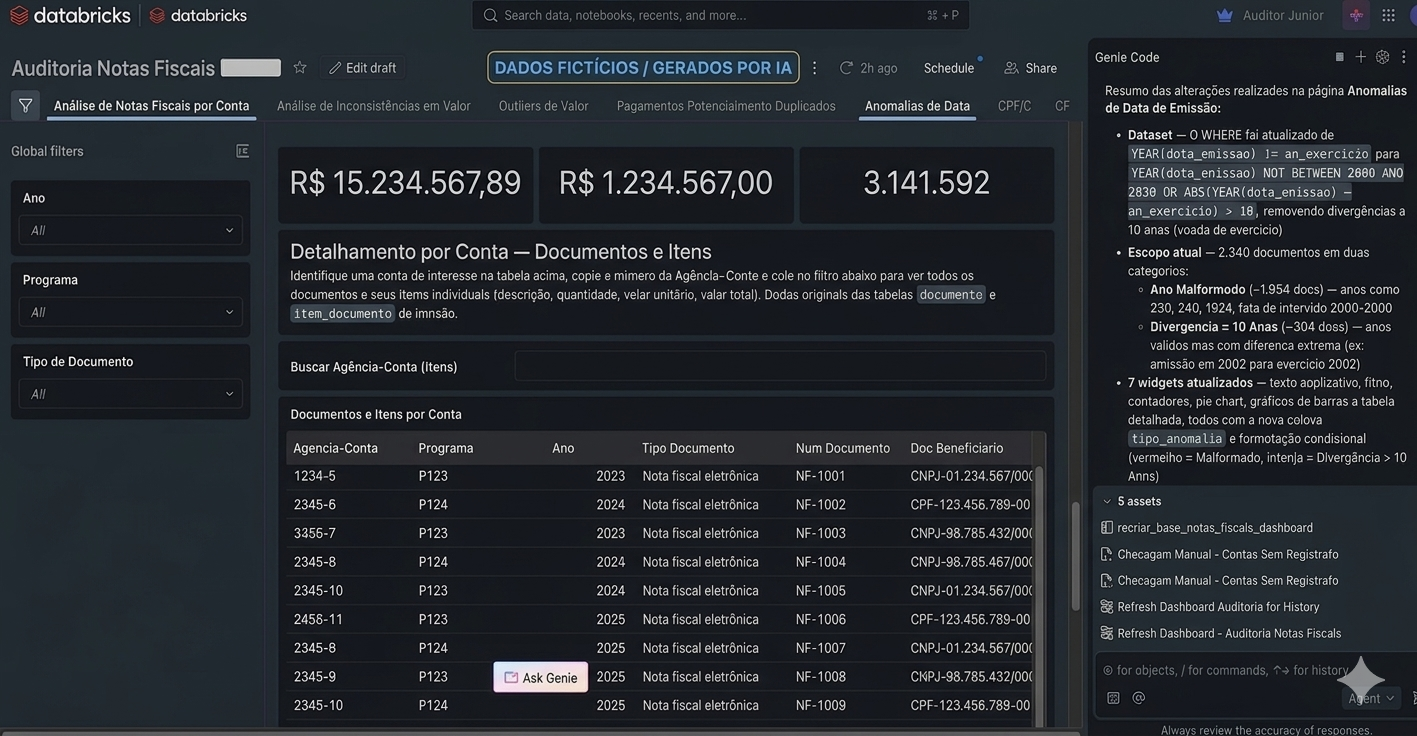
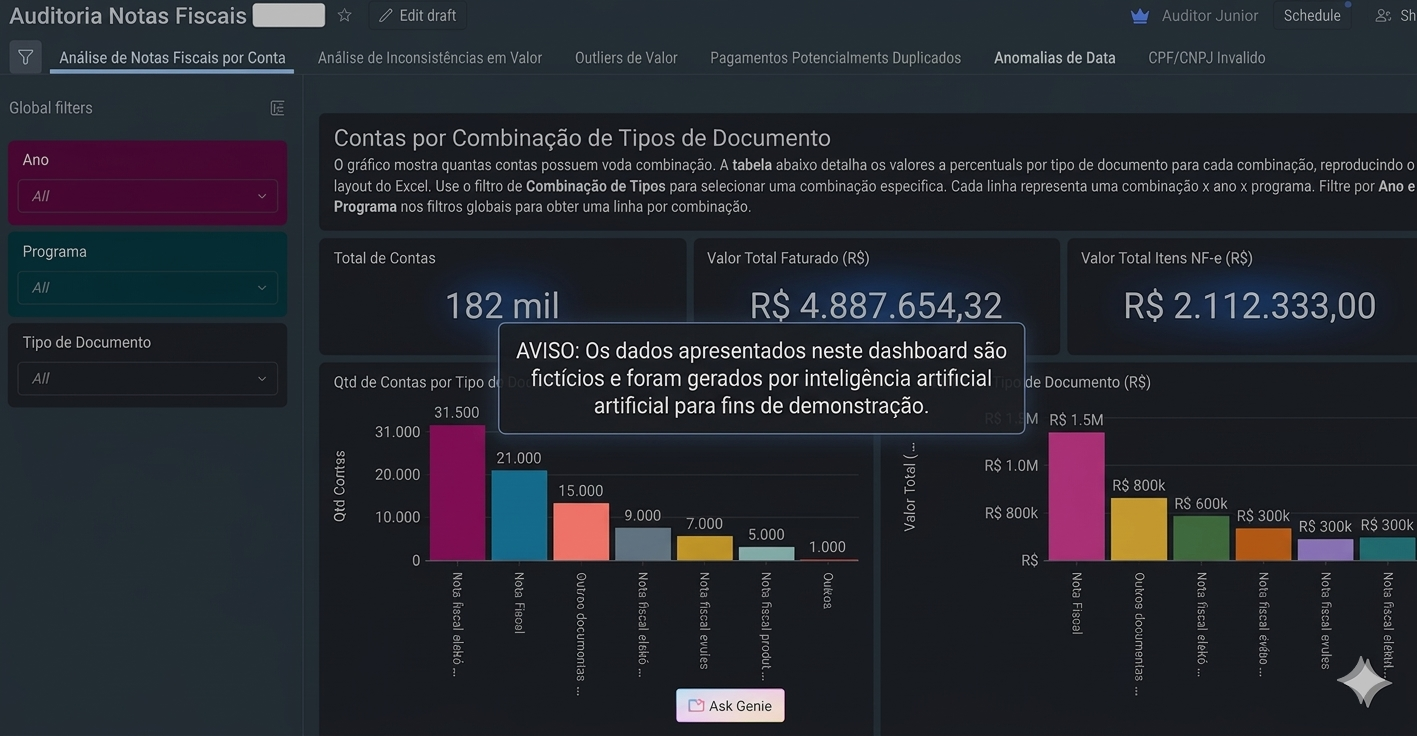
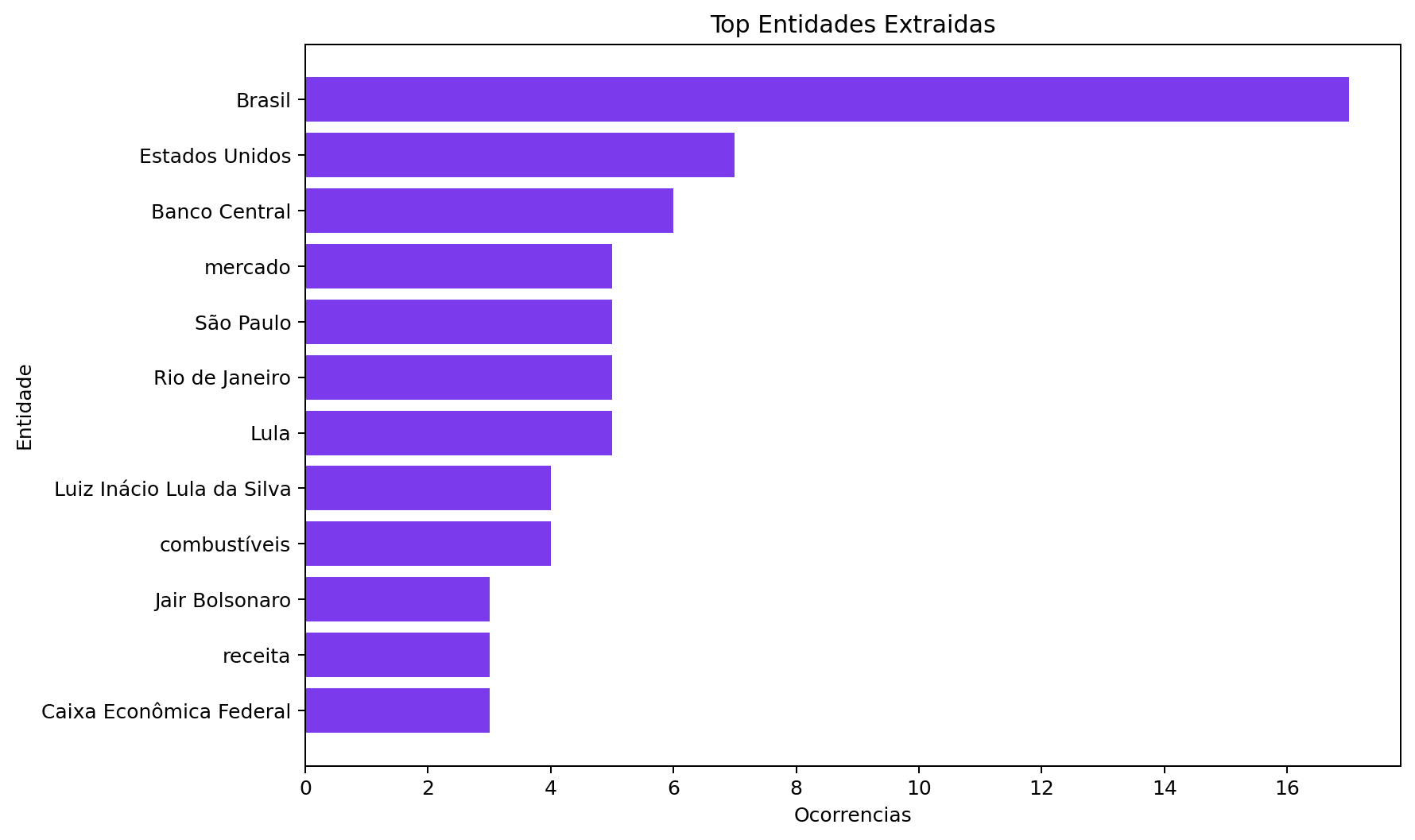
Invoice audit with PySpark, Databricks and Genie
Big data analytical engineering to investigate transaction
inconsistencies, with analytical tables, PySpark queries and a dashboard.
Impact: around 20% of inconsistencies detected
and audit time cut in half.
Documents and NLP
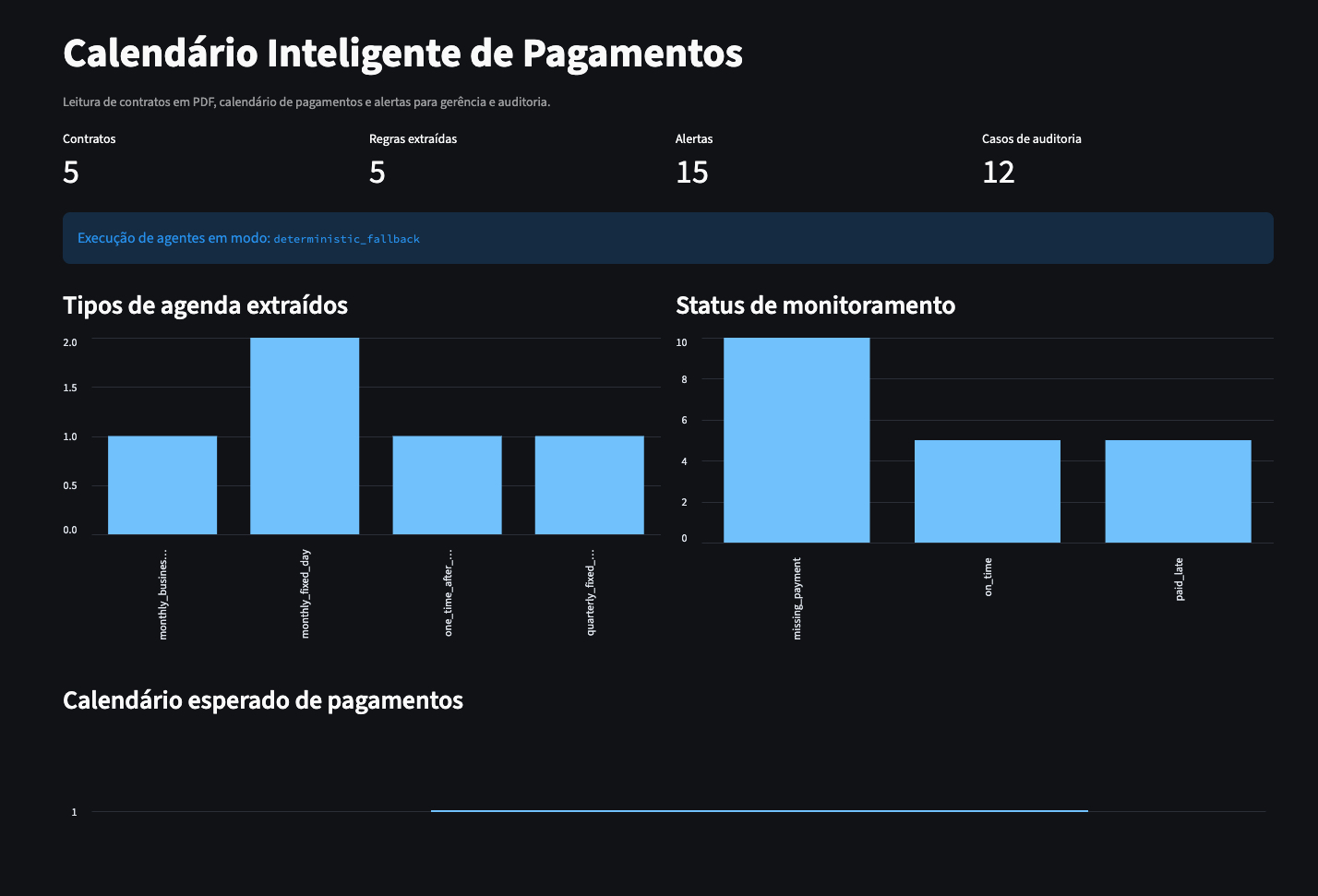
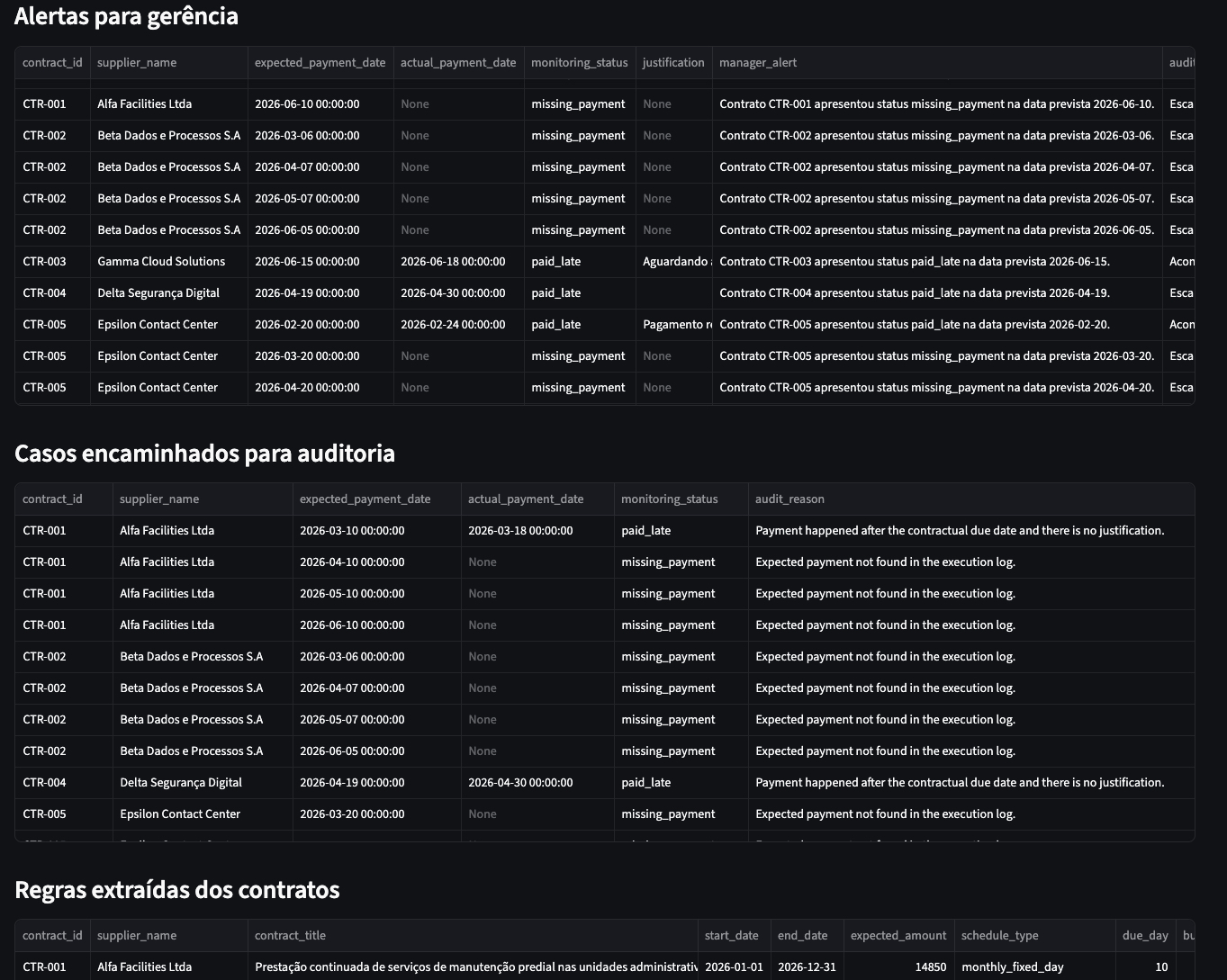
Contract reading and payment calendar with AI
Extraction of financial clauses from PDF contracts, expected payment
calendar construction and divergence monitoring.
Impact: contracts paid on the correct dates,
generating direct financial savings and tighter internal audit
control.
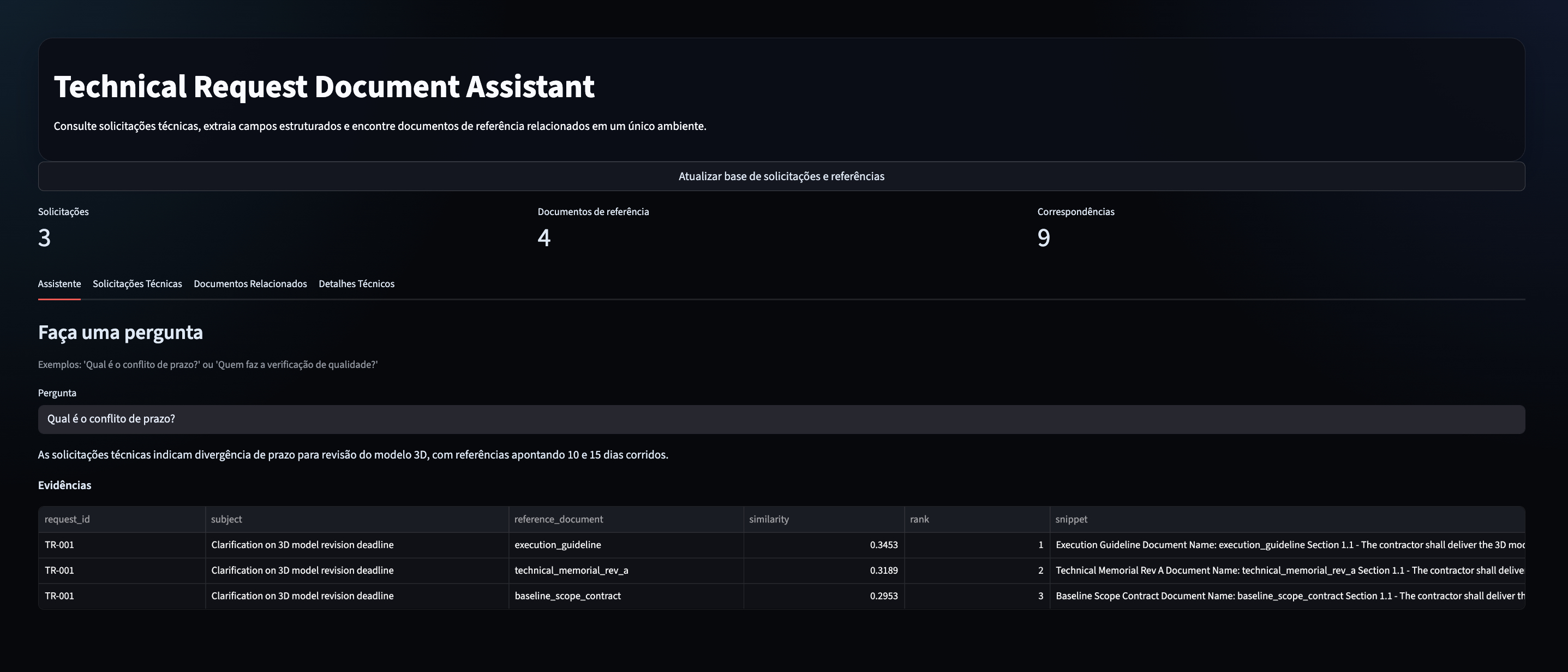
Search and RAG
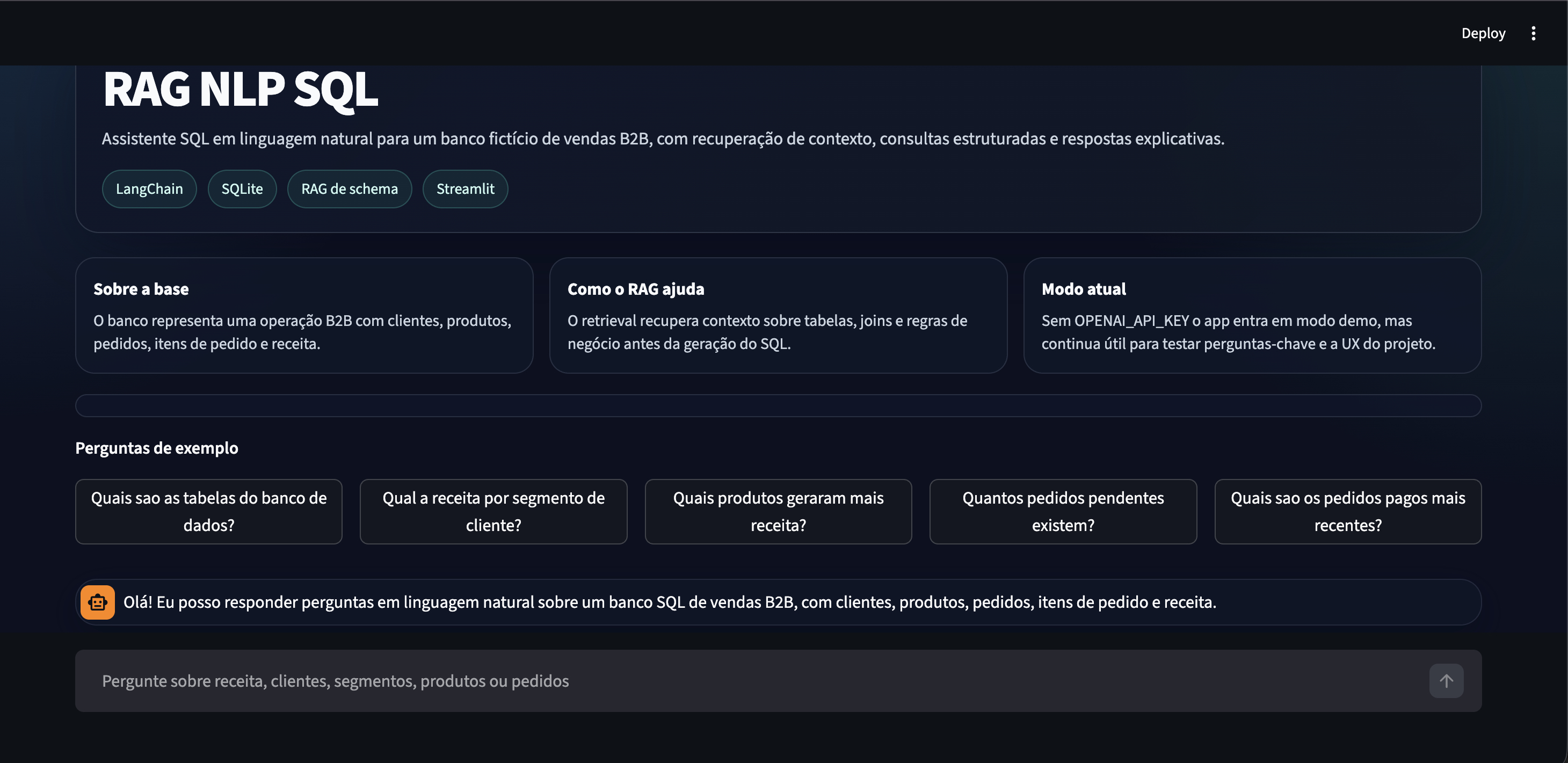
RAG NLP SQL with LangChain, OpenAI and SQLite
Natural language questions over a relational database, combining
semantic schema retrieval with SQL generation and execution.
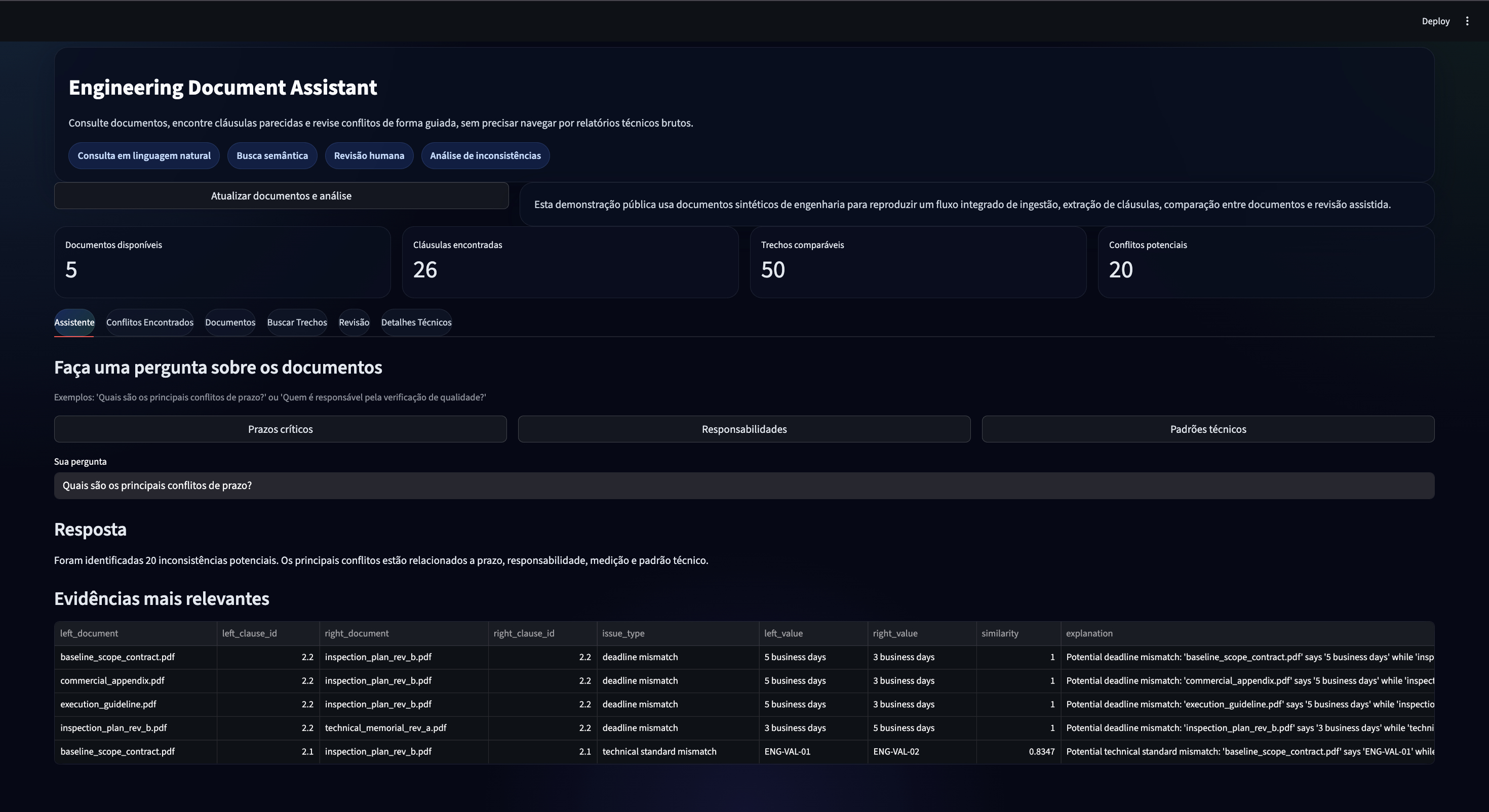
Agents and platform
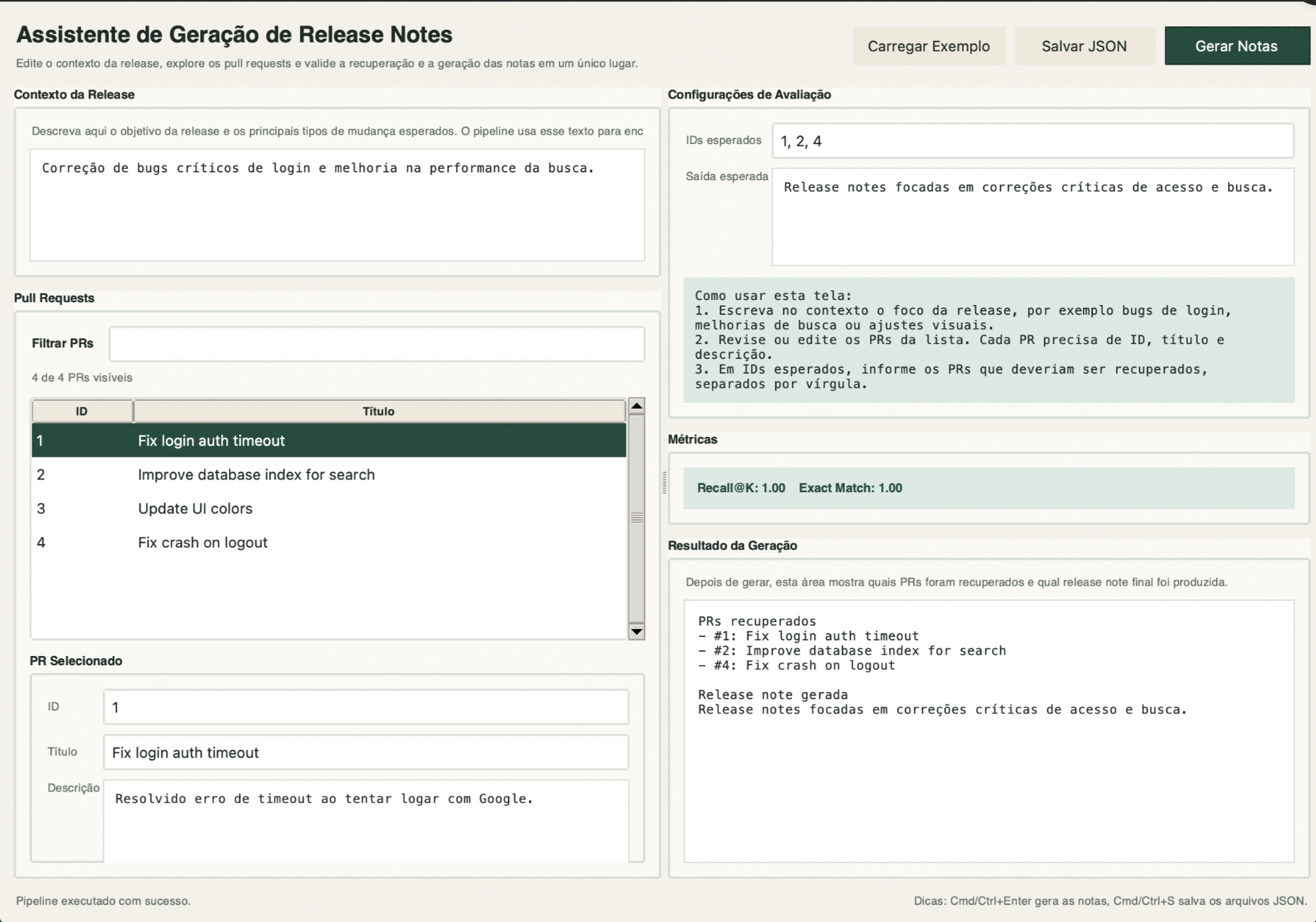
MCP Docs Assistant with FastMCP and BM25 search
Read-only MCP server for querying local documentation, exposing
resources, tools and prompts to MCP-compatible clients.